搜索到
47
篇与
的结果
-

-
-
-
-
-
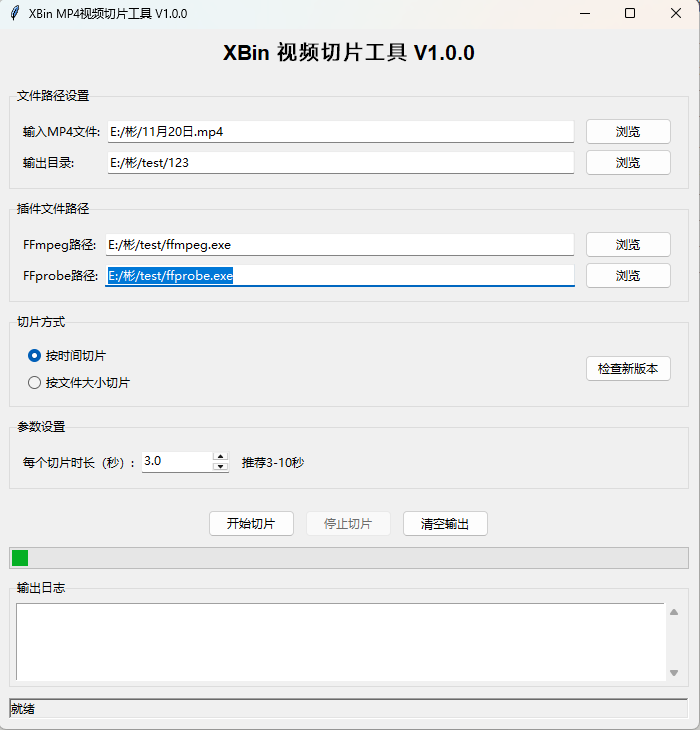
【最新版本】2025彩虹易支付程序源码+开源版无加密  ### 【最新版本】彩虹易支付更新内容: 彩虹易支付系统程序,最新版本 源码无任何加密,可支持二开 功能全,操作简单,适合做支付、收款、管理用。 {timeline} {timeline-item color="#19be6b"} 2025/08/26: 1.增加渠道交易单号查询 2.增加检测单个支付账号订单支付速度自动封禁账号 3.公共静态资源CDN可选择本地 4.平板&安卓模拟器支付时调整为不自动跳转支付宝微信 5.支付宝身份认证支持海外身份证件 6.支付宝安全发新增转账场景报备功能 {/timeline-item} {timeline-item color="#ed4014"} 2025/08/15: 1.修复支付宝付款记录导出乱码问题 2.增加管理员短信通知方式 3.修复微信支付V3切换平台公钥过程中无法回调 4.商户后台增加导出订单功能 5.后台订单列表新增批量选中执行回调通知 6.交易投诉可按时间查询,增加导出功能 {/timeline-item} {/timeline} 测试环境 nginx 1.20 php7.4 mysql5.6 设置伪静态: ```ada location / { if (!-e $request_filename) { rewrite ^/(.[a-zA-Z0-9\-\_]+).html$ /index.php?mod=$1 last; } rewrite ^/pay/(.*)$ /pay.php?s=$1 last; } location ^~ /plugins { deny all; } location ^~ /includes { deny all; } ``` {alert type="success"} 该程序源码原版全解无加密无后门。 疑问联系微信:ibin0513 {/alert} ## 推荐插件 拉卡拉支付插件:https://blog.52bin.cn/340.html
-
Python常规代码 ## 学习1-条件判断 ```python 炒饭 = 45 水饺 = 50 鸡腿 = 60 点餐=input('想吃什么?A:炒饭,B:水饺。 ').upper().strip() # 以下属于函数直接放后面,简写 # 点餐 = 点餐.upper() # 全部转换为大写 # 点餐 = 点餐.strip() # 去掉空格 加餐=input('请问你是否需要加鸡腿?Y:是,N:否。 ').upper().strip() if 点餐=="A": if 加餐=="Y": print(f"当前炒饭加鸡腿的价格是{炒饭+鸡腿}元") else: print(f"炒饭的价格是{炒饭}元") elif 点餐=="B": if 加餐=="Y": print(f"当前炒饭加鸡腿的价格是{水饺+鸡腿}元") else: print(f"水饺的价格是{水饺}元") else: print("对不起,没有这个产品") ``` ## 学习2-列表函数 ```python 打招呼="大家好,我是你大哥!,你知道吗!" print(len(打招呼)) #使用len,获取字符长度 print(list(打招呼)) #使用list,拆分所有的字为列表 print(打招呼.split(",")) #使用split,使用文本中包含的特定符号进行分割成列表 print(打招呼.find("我")) #查找对应索引值位置,未找到时会返回-1 #--------------------------------------------- 菜单=["炒饭","水饺","牛肉面","烤羊肉","鸡腿","烤鱼"] 菜单2=["蛋糕","冰淇淋"] #----------【取值】---------- print(len(菜单)) #使用len,获取列表数量 print(菜单[1]) print(菜单[1:3]) #取中间值(顾前不顾后,3的值不包含) print(菜单[1:]) #取索引1与之后的值 print("-".join(菜单)) #使用join将列表用特定符号连接起来,可以为空 print(菜单.index("牛肉面")) #1.获取数据对应位置,得到索引值,列表中多个相同值,会取第一个 print(菜单.index("牛肉面"),3) #2.获取数据对应位置,得到索引值,增加值,可以从当前索引值往后查找 #----------【增加修改】---------- 菜单[1] = "肉卷" #将列表对应索引值的内容进行修改替换 菜单.append("烤鸭") #使用append方法,添加一个值到列表后面 菜单.extend(["烤肉","烤鱼"]) #使用extend方法,可以设一个列表内容添加在后面 print(菜单+菜单2) #使用相加的方式将两个列表拼接 菜单.insert(1,"水煮肉片") #使用insert方式插入数据到指定位置,还可以使用列表方式插入["烤肉","烤鱼"]【会变成二维列表】 #----------【删除】---------- 菜单.remove("水饺") #使用remove删除列表中的对应内容 菜单.pop() #为空时,默认删除最后一个函数 ,可以设置索引值删除对应内容 被删除的元素 = 菜单.pop(2) #可以打印删除的元素并赋值 菜单.clear() #清空列表 #----------【判断】---------- if "水饺" in 菜单: ##使用in判断对应值是否在列表中 使用not in可以取反 print("炒饭在列表中") #----------【排序】---------- 菜单.sort() #使用sort将相似的内容进行重新排序 菜单=sorted(菜单,reverse=False) #与sort类似,但此方式可以修改降序升序的排序方式,True为降序 False未升序 菜单.reverse() #将列表中内容前后逆转 print(菜单) ``` ## 学习3-循环函数 ```python 菜单 =["炒饭","水饺","牛肉面","鸡腿","烤鸭"] 饮料 =["可乐","雪碧","芬达"] for 餐品 in 菜单: #餐品为变量,将菜单的每一项赋值给餐品,打印输出来 print(餐品) for 文字 in "学习Python技术" : #字符串也可以依次循环打印出来 print(文字) #----------【for循环结束、跳过】---------- for 餐品 in 菜单: #使用break 终止循环 if 餐品 == "牛肉面": break print(餐品) for 餐品 in 菜单: #使用continue 跳过当前循环 if 餐品 == "牛肉面": continue print(餐品) #----------【for嵌套for】---------- 数量=0 for 餐品 in 菜单: #嵌套for循环,将每个元素进行搭配,类似数学中的笛卡尔积 for 饮品 in 饮料: print(f"{餐品}搭配{饮品}") 数量+=1 print("一个有"+str(数量)+"搭配!") #----------【for加if判断区分列表】---------- 数列=[1,2,3,-4,5,-6] 正数=[] 负数=[] for 数值 in 数列: if 数值>0: 正数.append(数值) else: 负数.append(数值) print(f"正数:{正数}\n负数:{负数}") #----------【for执行条件】---------- for 变量 in range(3): #使用range设置循环次数 print(变量) for 变量 in range(3,10): #range(起始值,结束值) print(变量) for 变量 in range(1,10,2): #range(起始值,结束值,递增值) print(变量) ```
-
【最新】Like Girl v5.2.1 情侣小站开源版  【最新】Like Girl v5.2.1版本 情侣小站开源版 更新内容: 1.新增一键数据库安装功能,简化系统部署流程,提升新手小白安装网站初始化效率。 2.集成图片上传功能,支持用户便捷管理与一健上传图片资源。 3.在页面右下角增设悬浮功能按钮,集成“返回顶部”与“返回首页”快捷操作,提升用户页面导航与跳转体验。 4.优化留言板界面,修复QQ头像显示功能及IP地址获取机制,同步对UI进行视觉升级,提升整体美观度与交互一致性。 5.对恋爱相册模块进行性能优化,改进内容加载逻辑,并新增底部“加载更多”按钮,增强用户体验与内容浏览流畅度。 作者:Ki ## 源码下载: 隐藏内容,请前往内页查看详情 ## 图片上传功能插件: 上传图片插件:https://blog.52bin.cn/46.html
-
【插件】LikeGirlv5.2.1图片上传功能插件 ### 一、图片上传功能插件 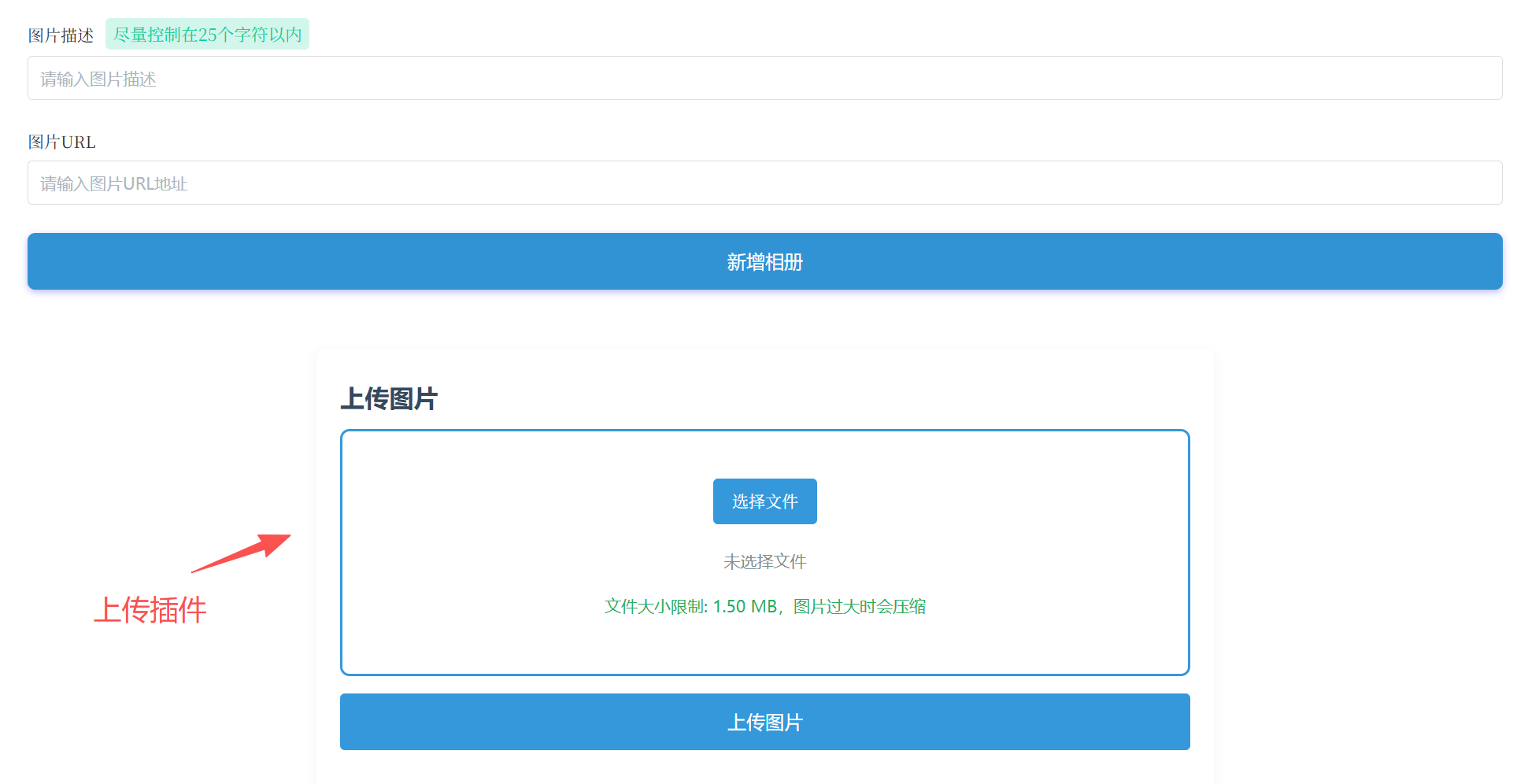 ## 教程视频 {dplayer src="https://file.52bin.cn/Vid/2026-01/UpImg/video.m3u8"/} #### 1.下载插件包: 插件包下载地址:[需插入上传代码] https://52bin.lanzouq.com/iJia33gdxkhi {alert type="warning"} 一健替换插件包下载(懒人包): https://52bin.lanzouq.com/ij6O83gdxg0h 说明:懒人包无需按照以下方式手动改代码。 只需用你那勤劳的双手,将懒人包上传到网站根目录,解压压缩包覆盖即可,登录后台就可以看到上传工具。 {/alert} {alert type="success"} 2026/1/7 更新优化BUG:解决上传被外部调用的漏洞,增加验证功能! {/alert} #### 2.上传插件包: 将上传插件包上传到网站根目录并解压 #### 3.插入上传代码: 在网站根目录【admin】文件夹中找到以下文件(这些文件是需要添加上传功能的页面) 点点滴滴文件:littleAdd.php、modlitt.php 恋爱相册文件:loveImgAdd.php、modImg.php 恋爱清单文件:lovelistAdd.php、modlist.php 以上文件夹都需要插入上传代码 ```html ``` 将以上三行代码插入到需要添加上传功能的PHP文件内 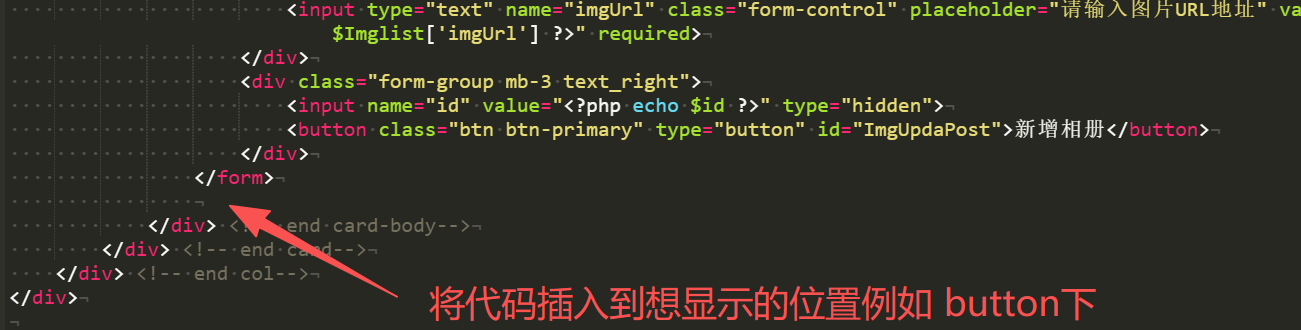 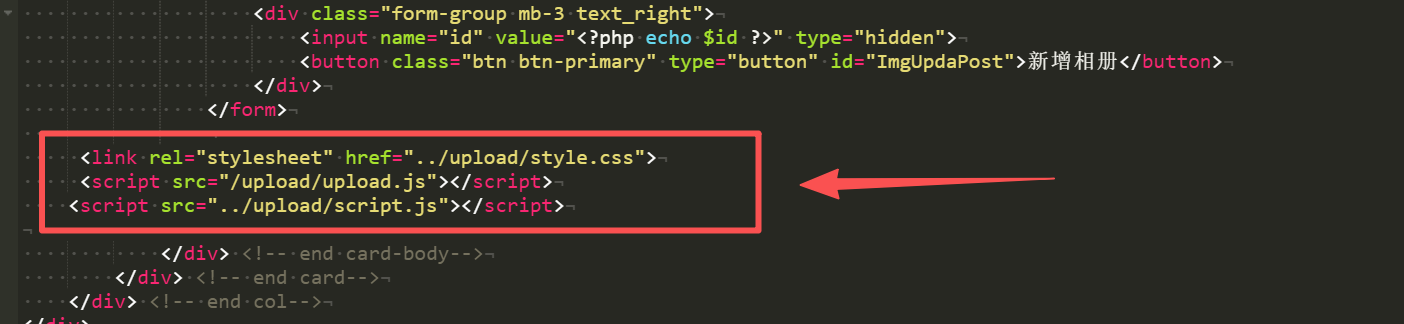
-
Nuitka打包Python程序全面指南 ## Nuitka打包Python程序全面指南 Nuitka是一个强大的Python编译器,能够将Python代码编译成C/C++代码并进一步编译为本地机器码,显著提升程序执行效率并简化部署过程。以下是使用Nuitka打包Python程序的详细指南。 ## 一、Nuitka简介与优势 Nuitka是一个完全兼容Python 2.6到3.12的Python编译器,它通过将Python代码转换为优化的C++代码并编译为本地可执行文件,提供接近原生代码的执行性能。与PyInstaller等打包工具相比,Nuitka具有以下显著优势: 性能提升:编译后的程序比解释执行的Python代码快2-10倍,特别适合计算密集型任务 更小的文件体积:通过优化和压缩技术生成更紧凑的可执行文件 更好的兼容性:支持几乎所有Python标准库和主流第三方库 跨平台支持:可生成Windows、Linux和macOS平台的可执行文件 代码保护:编译后的二进制文件比传统打包工具更难反编译 二、安装与环境准备 ## 1. 基础安装 使用pip直接安装Nuitka: ```abap pip install nuitka ``` 建议在虚拟环境中安装以避免依赖冲突: ```abap conda create -n EXE python=3.12.8 conda activate EXE pip install nuitka ``` ## 2. 系统依赖 Linux系统需要安装编译工具: ```abap sudo yum install -y gcc gcc-c++ python3-devel # CentOS sudo apt install patchelf # Ubuntu[1](@ref) ``` Windows系统需要安装MinGW64或Visual Studio的C++编译工具 ## 3. 可选工具 安装UPX可进一步压缩生成的可执行文件: ```abap wget https://github.com/upx/upx/releases/download/v4.0.2/upx-4.0.2-amd64_linux.tar.xz tar -xf upx-4.0.2-amd64_linux.tar.xz sudo cp upx-4.0.2-amd64_linux/upx /usr/local/bin/ ``` ## 三、基本打包命令 {message type="success" content="小经验提示: 1.打包一定要中文路径,不然会出现一些问题 2.建议放C盘打包,实测速度更快"/} 1. 简单打包 生成独立目录结构的可执行文件: ```abap nuitka --standalone --remove-output main.py ``` 生成单个可执行文件: ```abap nuitka --standalone --onefile --remove-output main.py ``` ## 2. 常用参数说明 ```abap --standalone:创建独立可执行文件,包含所有依赖 --onefile:将所有文件打包成单个可执行文件 --remove-output:删除临时缓存文件 -o:指定输出文件名 --enable-plugin=tk-inter:启用Tkinter插件支持 --windows-disable-console:禁用控制台窗口(适用于GUI应用) --include-data-files:包含额外数据文件 ``` ## 四、处理不同类型应用的打包 1. GUI应用打包 Tkinter应用: ```abap nuitka --standalone --onefile --enable-plugin=tk-inter your_gui_app.py ``` PyQt5应用: ```abap nuitka --standalone --onefile --enable-plugin=pyqt5 --include-module=PyQt5 your_pyqt_app.py ``` ## 2. Web应用打包 安装nuitka-web后打包Flask应用: ```abap pip install nuitka-web nuitka-web --flask your_flask_app.py ``` 或手动指定静态文件目录: ```abap nuitka --standalone --onefile \ --include-data-dir=templates=templates \ --include-data-dir=static=static \ --include-package=flask \ app.py ``` ## 3. 数据处理应用 打包使用NumPy、Pandas等科学计算库的应用: ```abap nuitka --standalone --onefile --include-package=numpy --include-package=pandas your_data_app.py ``` ## 五、高级优化与调试 1. 性能优化选项 ```abap --optimize=2:启用最高级别优化 --lto=yes:启用链接时优化,减小文件体积 --python-flag=no_asserts:禁用断言,提升性能 --jobs=$(nproc):使用多核并行编译加速打包 ``` 2. 调试选项 ```abap --debug:生成包含调试信息的二进制文件 --show-scons:显示SCons构建系统的详细输出 --show-memory:显示内存占用情况 ``` 3. 交叉编译 指定目标平台进行交叉编译: ```abap nuitka --standalone --recurse-all --target package:dir=bin,all your_script.py ``` ## 六、常见问题解决 缺少依赖库:手动包含缺失的包 ```abap nuitka --standalone --onefile --include-package=missing_package your_script.py ``` 文件体积过大:使用UPX压缩 ```abap nuitka --standalone --onefile --enable-plugin=upx your_script.py ``` 打包tkinter报错:确保主代码中添加import tkinter as tk Windows兼容性问题:使用--mingw64而非VS编译器 图标处理:PNG图标需安装imageio库,建议使用ICO格式 ## 七、最佳实践建议 版本选择:Nuitka 1.9.5和最新版本较为稳定 环境隔离:推荐使用虚拟环境而非Anaconda基础环境 路径处理:避免使用中文或空格路径 依赖管理:对于复杂项目,考虑将核心代码打包为pyd文件 持续集成:可集成到GitHub Actions等CI/CD流程中 通过合理配置Nuitka,您可以将Python应用高效地打包为高性能的可执行文件,实现真正的"一次编写,到处运行"。根据项目需求选择适当的打包策略和优化选项,可以在性能、文件体积和兼容性之间取得最佳平衡。 {callout color="#36e0f7"} ### 动态导入的模块未正确打包 pywinauto依赖comtypes.stream模块,但该模块可能通过动态导入方式加载(如运行时生成),导致PyInstaller/Nuitka等工具在打包时未能自动包含此模块 若使用Nuitka:添加--include-module参数 ```abnf nuitka --standalone --onefile --include-module=comtypes.stream Python.py ``` {/callout}
-
数据库SQL【插入、修改、删除语句】基本语法——笔记 ## 数据库SQL【修改、删除语句】基本语法 ```abap #——————————【插入数据】———— ## 1.INSERT INTO movie指定要向movie表中插入数据,加上(指定要插入数据的列) insert into movie(id,title,director,release_date,length_minutes) values (23,'活着','张艺谋','1994-05-18',125),(24,'活着','张艺谋','1994-05-18',125) #——————————【修改数据】———— ## 1.修改对应数据:【UPDATE movie】指定要更新 movie 表中的数据 如果没有【WHERE】条件,会更新表中所有记录 update movie set length_minutes = 50,director='姜文' where title = '无人区' ## 2.修改对应数据:只更新ID值在1到5之间(包含1和5)的记录【BETWEEN】是范围运算符 update movie set length_minutes = 50,director='姜文' where id between 1 and 5 #——————————【删除行数据】———— ## 1.删除一整行数据,对应条件 delete from movie where title = '无人区' #——————————【删除列数据】———— ## 1.删除一整列数据,对应条件director列,可以删除多个列,套用【drop column】 alter table movie drop column director,drop column length_minutes #——————————【删除所有数据】———— ## 1.删除movie表的所有内容 delete from movie ## 2.删除movie的表 drop table movie ```
-
SQL 主键(Primary Key)——笔记  ## SQL 主键(Primary Key) 主键是关系型数据库中用于唯一标识表中每一行记录的列或列组合。它是数据库表设计中的一个重要概念。 ## 主键的特性 唯一性:主键值必须是唯一的,不能重复 非空性:主键列不能包含NULL值 不可变性:主键值一旦设定,通常不应更改 ## 主键的类型 自然主键:使用业务中自然存在的标识(如身份证号、学号) 代理主键:专门为表创建的标识(如自增ID、GUID) ### 设置方法 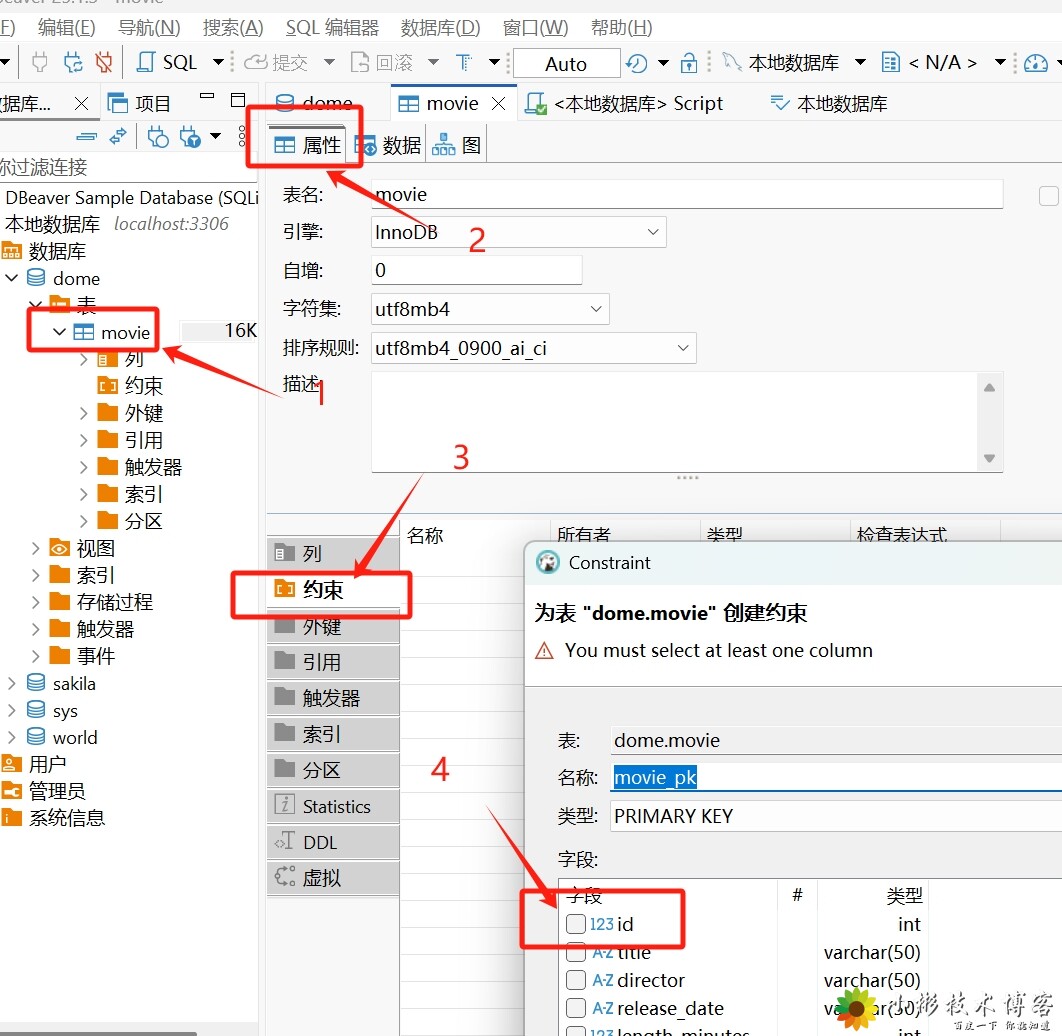
-
数据库SQL【查询语句】基本语法——笔记 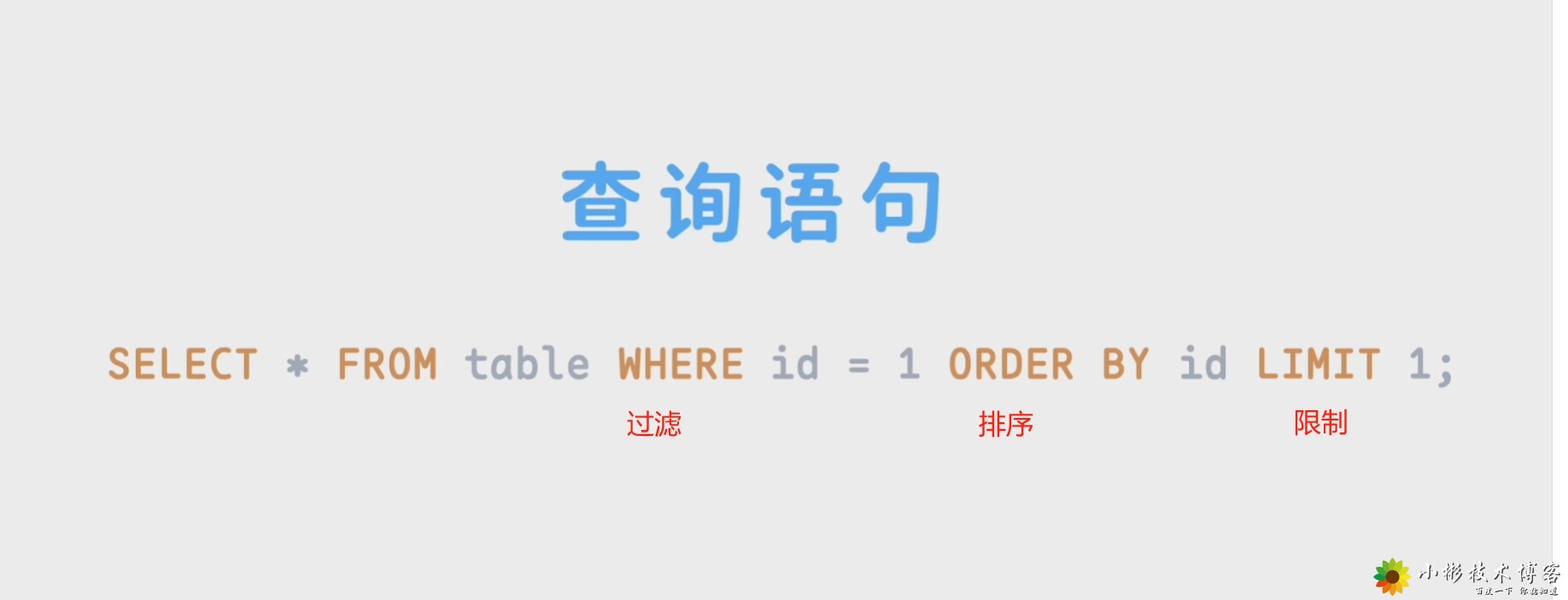 ```abap ## 1.##movir中提取title和director列的表 select title,director from movie ## 2.movir中提取使用*所有列的表 select * from movie ## 3.提前director列数据,通过【distinct】语句取掉重复内容,根据director去重的数据,后面的release_date根据前面去重的数据一致 select distinct director,release_date from movie ## 4.使用【order by】语法对列表排序,默认为升序,尾部加个【desc】可以改变为降序 select * from movie order by release_date ## 5.前面加个【director】以导演名一列为排序,后面release_date以时间通过【desc】来降序 select * from movie order by director,release_date desc ## 6.使用【limit】语法输出列表的前5条 select * from movie limit 5 ## 6.使用【limit】语法前面加个3,将从第4行开始输出列表5条数据 select * from movie limit 3,5 ## 7.【where director=】 语法筛选出对应内容的数据 select * from movie where director='宁浩' ## 8.筛选出来的内容使用【and】与语句 时间列 >110分钟的数据 select * from movie where director='宁浩' and length_minutes > 110 ## 9.筛选出来的内容使用【or】或语句 筛出导演和时间 >110分钟的数据 select * from movie where director='宁浩' or length_minutes > 110 ## 10.筛选出来的内容使用【in】语句 筛出director列多个人的数据 select * from movie where director in('宁浩','姜文') ## 11.使用【between】语法,取length_minutes列下110到120区间的数据 select * from movie where length_minutes between 110 and 120 ## 12.筛选列中对应时间的列 select * from movie where release_date='2013-12-03' ## 13.【like】通配符筛选,筛选内容包含2013的字符,来达到赛选2013年份所有数据的功能 select * from movie where release_date like '2013%' ## 14.【like】通配符筛选,使用下划线_一个代表一个文字,这里可以赛选出3个字的导演名字 select * from movie where director like '___' ## 15.使用【year()】语法,提取日期中的年份,进行筛选 select * from movie where year(release_date)='2013' ## 15.使用【month()】语法,提取日期中的月年份,进行筛选 select * from movie where month(release_date)='12' ```